Generalisation Error
The generalisation error quantifies a model’s ability to adapt and perform accurately on new, previously unseen data drawn from the same distribution as the training set. It is a fundamental concept for understanding and diagnosing model behaviors like overfitting.
The term “generalisation error” can refer to two closely related concepts:
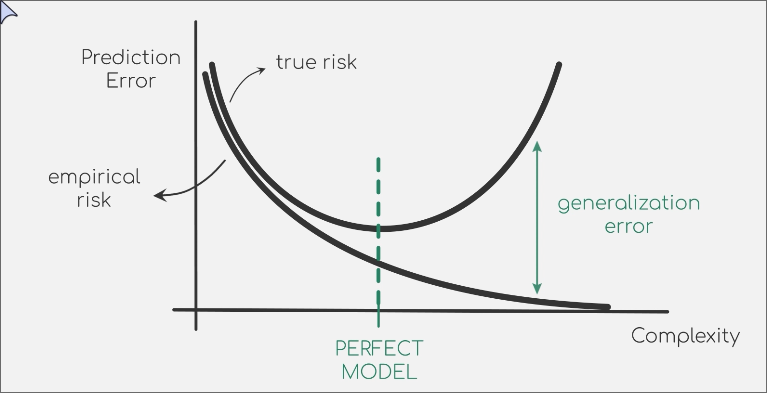
The True Risk (): Most commonly, the generalisation error is used synonymously with the true risk. It represents the expected loss of the model on the entire underlying data distribution .
In this sense, the goal of machine learning is to find a model with the lowest possible generalisation error.The Generalisation Gap: More precisely, it can refer to the difference between the true risk and the empirical risk (the error on the training set). This gap is a direct measure of overfitting.
A large generalisation gap indicates that the model has memorized the training data (low ) but fails to generalise to new data (high ). This phenomenon is known as overfitting.
The Goal of Learning
The objective of a learning algorithm is not simply to minimize the empirical risk, , but to minimize the true risk, . This involves a trade-off: finding a model complex enough to capture the underlying patterns in the data but not so complex that it learns the noise specific to the training set. Theoretical frameworks like Probably Approximately Correct (PAC) learning aim to provide probabilistic bounds on the generalisation error, ensuring that a model with low empirical risk will also have low true risk with high probability.