machine-learning transformers attention
Definition
Scaled Dot-Product Attention
where:
- is the query vector representing what the current token is searching for.
- is the key vector representing what each token contains.
- is the value vector representing the actual content to be aggregated or propagated.
- is the softmax function.
Note that this is usually computed as a batch across all tokens int he sequence fr efficiency.
Shape Visualisation
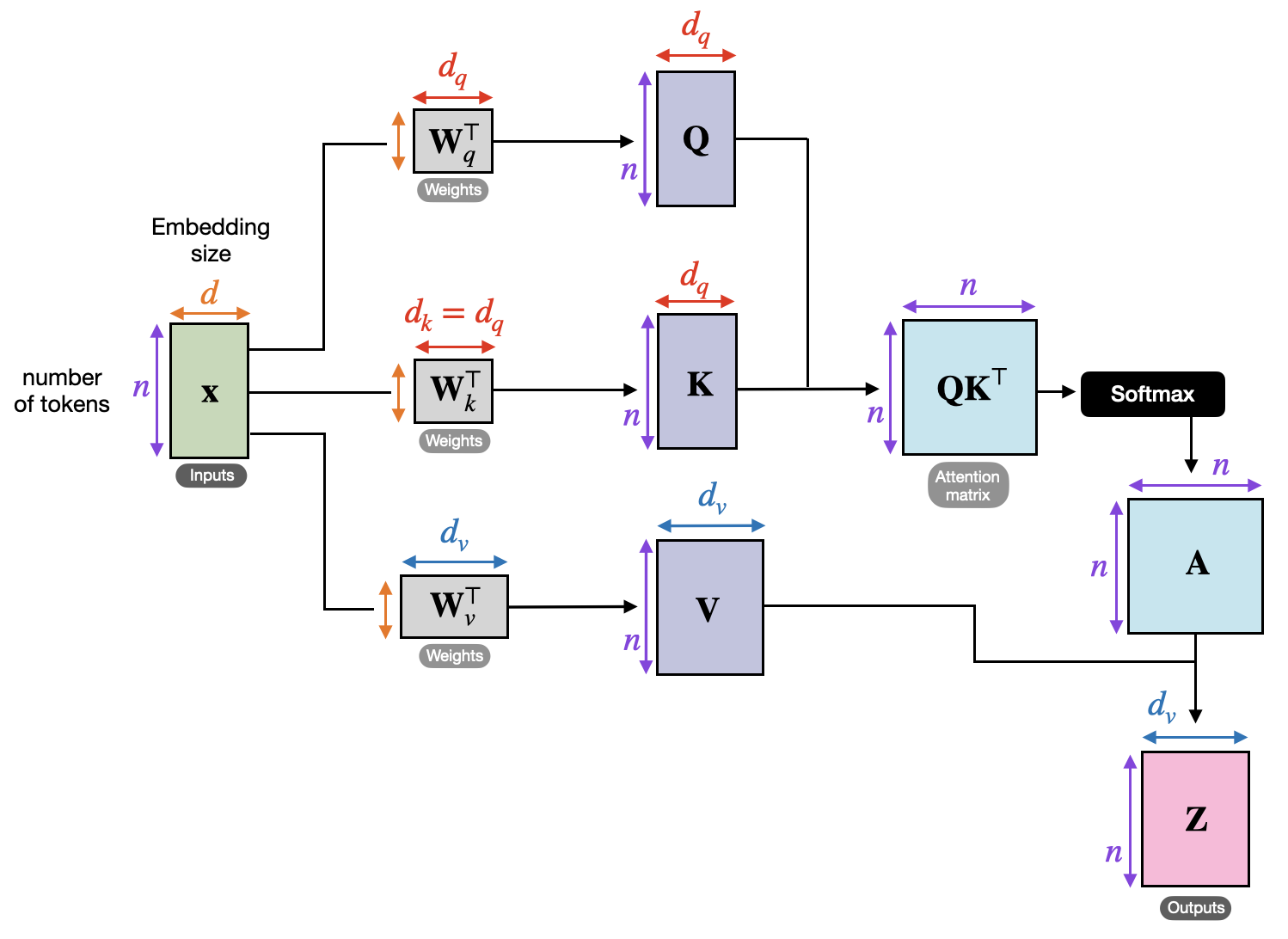
Taken from 1.