Exercise 1
Instruction
Consider the following scheduling problem: There is one machine, which is unavailable for a given period (i.e., no job can be scheduled during this time). The jobs are released at time and cannot be preempted. We want to compute a schedule that minimises lateness.
Is the problem above NP-hard or polynomial time solvable? In case of the former, provide a reduction. In case of the latter, provide an algorithm with a correctness argument and runtime analysis.
Minimising lateness means minimising the metric
where is the completion time and is the deadline of job . So the schedule should minimise the maximum lateness of the jobs.
We reduce from subset sum by forcing an unavailable time interval . Given a subset sum instance
Let
Further, assume that is an upper bound of , i.e., . Otherwise, if , then the instance is immediately a no-instance.
Next, create one scheduling job for each number . Set the processing time to , the deadline to , and the release time to , i.e.,
We make the one machine we have unavailable during
and no job can be preempted. We want to decide whether
i.e., no job is late and thus must finish no later than the common deadline .
This completes the reduction: the subset sum instance is mapped to the scheduling instance with jobs , common deadline , and one unavailable interval .
Correctness
The interval before the gap has length , and the interval after the gap has length . Since all deadlines are , a schedule with must fit all units of work into these two intervals. No further gaps are useful, since any idle time outside the unavailable interval only makes completion times later.
If the jobs scheduled before the unavailable interval have total processing time , then
Therefore, the remaining work, i.e., the work on the right side of the gap, is . This work cannot be processed during , because the machine is unavailable there. Hence, the earliest possible start time for the remaining work is . Even if the machine works without idle time after the gap, it still needs time units to process the remaining jobs. Hence, the last completion time is at least
To have , every job must complete by the deadline , hence:
Above, we already said , so we have
So any schedule with must fill the whole left-sided interval of the unavailability gap of the machine. The jobs before the gap therefore correspond to a subset of , i.e., the processing times, whose sum is exactly .
First, suppose the subset sum instance has a subset with
Schedule the corresponding jobs in , wait for the unavailable interval , and then schedule the remaining jobs after time . The remaining processing time is , so the last job completes at
Thus every job completes no later than the common deadline . Therefore, the constructed scheduling instance has a schedule with
Conversely, suppose the constructed scheduling instance has a schedule with
Then all jobs complete by time . Let be the total processing time of the jobs scheduled before the unavailable interval. As shown above, this implies . Since each processing time is exactly one number from the subset sum instance, the jobs before the gap define a subset with
So the original subset sum instance is a yes-instance exactly when the constructed scheduling instance admits a schedule with .
The mapping is polynomial: it creates one job per number and computes only , , and the unavailable interval . Since the correctness proof shows equivalence with subset sum, deciding whether the constructed instance has a schedule with is NP-hard. Therefore, computing a schedule that minimises maximum lateness for one machine with one unavailable interval is also NP-hard.
Exercise 2
Instruction
Consider the problem
where is a function (that may be different for each job ). For example, if
then the problem is equivalent to
(i.e., minimising the sum of completion times with preemption constraint). For another example, if
then the problem is then equivalent to
(i.e., maximising throughput with preemption constraint).
First, show that if the functions are nondecreasing (i.e., for , ), there exists an optimal schedule that is nonpreemptive.
Second, answer the following question: “Does the result hold for arbitrary functions ?“. Briefly justify your answer.
Let be a non-decreasing function for a job , i.e.,
In other words, if the completion time is before completion time , then preserves that before-after relation.
An optimal schedule of a scheduling problem is a solution where is minimal. In the problem above, it means that
where is the smallest (best) feasible objective.
(1)
We construct a new schedule that processes jobs non-preemptively in the order
Therefore, the completion time of job in is the sum of preceding (reflexive) processing times:
Let be an optimal preemptive schedule with , and let the jobs be ordered by their completion times in :
In , by time , all jobs have completed. Therefore, must have processed at least
units of work by time . Given there’s only one machine, no parallelism is allowed, i.e.:
From above, we know that
In other words, every job completes no later in than in . Further, we know that is non-decreasing, thus:
Hence:
By definition is already optimal, i.e., the smallest feasible value. We conclude that
which means that both and are optimal. Given that is non-preemptive, there exists an optimal non-preemptive schedule .
(2)
No. The following two-job instance is a counterexample.
Consider two jobs with
In any non-preemptive schedule, the completion times are either
With preemption, however, we can schedule
which yields
Now define arbitrary objective functions that reward exactly these preemptive completion times:
The preemptive schedule has objective value , while every non-preemptive schedule has objective value at least . Thus, for arbitrary functions , there need not exist an optimal non-preemptive schedule.
Exercise 3
Instruction
Let
Assume
Compute the prefix function, the suffix tree, and the suffix array of .
(Note: Some of the concepts in this exercise will be discussed in the lecture on 2 June.)
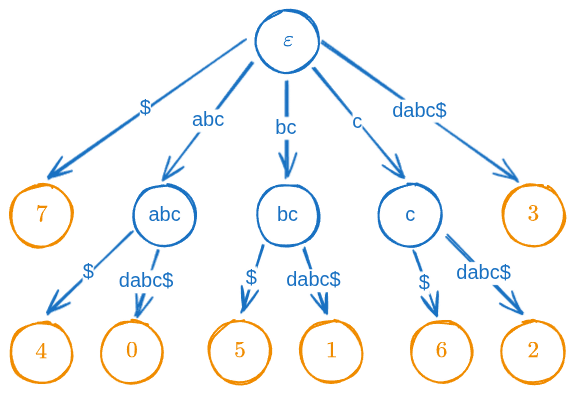
border aababcabcdabcdaaabcdabababcdabcabc
with a sorting order
$ < a < b < c < d,i.e., in lexicographic order,
$is the first suffix, a the second, etc.This makes
$the first suffix in lexicographic order. It also separates suffixes cleanly: for example,abc$is not hidden insideabcdabc$.First list all suffixes of :
start suffix shared prefix abcdabc$: abcbcdabc$: bccdabc$: cdabc$none abc$: abcbc$: bcc$: c$none Only have no shared prefixes, thus, they become direct leafs from the root. The suffix tree is the compressed trie of these suffixes
Each orange leaf stores the starting position of its suffix in $S$$.
Sort the same suffixes lexicographically and assign a
rankto each:
suffix rank $abc$abcdabc$bc$bcdabc$c$cdabc$dabc$Thus, my suffix array is:
Exercise 4
Instruction
In the lecture, the runtime analysis of the Knuth-Morris-Pratt Algorithm is an example of the sliding window technique. This technique can be applied in many problems with “linear” structure, as in the following example.
Suppose we are given as input a number and an array sorted in increasing order. The task is to find , such that .
The algorithm based on the sliding window technique for this problem is as follows. We start with and and repeatedly perform the following procedure:
- If , then we increase by .
- If , then we decrease by .
We stop when , when , or when . In the latter case, we conclude that no such and satisfy the requirement.
Your tasks for this exercise are:
- Determine the running time of the algorithm above (in notation, but with providing a bound which is as tight as possible).
- Argue that the algorithm correctly solves the problem.
(int, int) Search(Array a, int k)
assert a is sorted in increasing order
int n = |a|;
// 1-based indexing
int i = 1;
int j = n;
while i <= n and j >= 1 {
int s = a[i] + a[j];
if s == k {
return (i, j);
} else if s < k {
// left-side is not big enough
i += 1;
} else {
// right-side is too big
assert s > k;
j -= 1;
}
}
return null;
Runtime Analysis
In every loop iteration, exactly one of these happen (unless the algorithm immediately returns):
- , or
- .
Each iteration performs only constant-time work, i.e., , and we loop at most iterations given that
Further, we only search over , so the running time is . Hence
Correctness
Given an instance , where is sorted in increasing order.
If the algorithm returns a pair , then it has checked
Therefore, the returned pair is a correct solution.
Now suppose the algorithm returns . We show that every pointer move only discards candidates that cannot be part of a solution.
Sum too small
Assume that
Since is sorted increasingly, every still available right index satisfies
Hence
So is too small even with the largest still available right component, which means that no pair using can be a solution anymore and that it is safe to increase .
Sum too large
Assume that
Since is sorted increasingly, every still available left index satisfies
Hence
So is too large even with the smallest still available left component, which means that no pair using can be a solution anymore and that it is safe to decrease .
Thus, every step either returns a correct pair or removes only impossible candidates, so if the algorithm terminates with because or , no candidate pair remains although only impossible candidates were removed. Hence, no valid pair exists.
Therefore, the algorithm correctly solves the problem.
Exercise 5
Instruction
Given a string and a natural number , describe an -time algorithm to find the maximum border of , such that is a multiple of . Briefly justify the correctness and running time bound of your algorithm.
Given a string and a natural number , let . To do that, we can use the prefix function, as
So if we take , we have the longest border of
Let . If is divisible by , we can return . Otherwise, we have to find a smaller border that’s divisible by .
Example
Let . The longest border of is
If , then , so this border is not valid. We now need the next smaller border of .
Since is the current border, every smaller border of must also be border of . Thus, we can ask for the longest border of :
Pseudocode
String MaximumBorder(String S, int k) assert k >= 2 int n = |S|; compute prefix function π for S int ℓ = π(n-1); while ℓ > 0 and ℓ mod k != 0 { ℓ = π(ℓ-1); } return S[0 .. ℓ-1];
and
The borders of are
The prefix function first gives
Since , the algorithm jumps to the next smaller border:
Since , it returns .
Correctness
The algorithm starts with , which is the length of the longest border of .
Whenever the current is not divisible by , the border cannot be the answer, and
moves to the next smaller border of , because every smaller border of is also a border of the current border .
Thus, the loop visits the border lengths of from largest to smallest and stops at the first one divisible by , which is therefore maximal. If the loop reaches , no positive valid border exists, so returning is correct.
Runtime Analysis
Computing the prefix function takes time.
During the loop, strictly decreases because . Thus, the loop performs at most iterations, and each iteration does constant work.
Hence, the total running time is .
Exercise 6
Instruction
For a string , we want to find the length of the longest subsequence that has at least two distinct occurrences in . Here, two occurrences of a subsequence are distinct, if they differ in at least one index. More formally, we want to find the length of a longest string , such that for some
and
- for all (i.e., these indices encode the same subsequence); and
- there exists such that (i.e., the two occurrences are distinct).
Describe an -time algorithm to solve this problem. Briefly justify the correctness and running time bound of your algorithm.